Statistical Thinking for Business: A Decision-Making Framework
“Our new landing page converts 20% better!”
Based on what? 47 visitors over two days? That’s not evidence. That’s noise pretending to be signal.
Most business decisions are made with confidence that the underlying data doesn’t support. Small samples get treated as proof. Random variation gets interpreted as trends. Correlation gets confused with causation constantly. Whether you’re analyzing SEO performance or evaluating a marketing campaign, these errors cost real money.
I’ve made every one of these mistakes in my business. I’ve celebrated “wins” that were random noise. I’ve abandoned strategies that were actually working because of one bad month. I’ve confused correlation with causation in ways that wasted thousands of dollars. Statistical thinking isn’t about being good at math. It’s about asking the right questions before drawing conclusions.
The Base Rate Problem
Your first question should always be: What happens normally?
Your marketing campaign generated 15 leads. Is that good? You genuinely can’t know without the base rate. If you normally get 5 leads per week, 15 is impressive. If you normally get 20 leads per week, 15 is disappointing. The number by itself means nothing.
Base rate blindness shows up everywhere in business:
“We got 3 complaints this month.” Out of how many customers? Three complaints from 50 customers is alarming. Three complaints from 5,000 is excellent.
“Revenue was $50,000 this month.” What’s the normal range? If your typical range is $45,000 to $55,000, this is unremarkable.
“Conversion rate is 2.3%.” What’s industry average? What’s your historical average? Without comparison, you’re looking at a number in a vacuum.
Without base rates, you can’t distinguish good from bad, improving from declining, normal from genuinely anomalous. I keep a dashboard of my key metrics with 12-month trailing averages specifically because base rates prevent me from overreacting to individual months.
Establishing base rates:
Track metrics over time. Establish what “normal” looks like for your business. Note the range, not just the average. Good project management tools help you track this data consistently.
Normal might be “conversion rate between 2.0% and 2.8%, averaging 2.4%.” Now you can actually identify when something is genuinely different versus just fluctuating within the normal range.
Sample Size Intuition
Small samples lie. Consistently and confidently.
You flip a coin 4 times and get 3 heads. Is the coin biased? No. That outcome is completely normal for a fair coin. You just don’t have enough data to conclude anything.
In business terms:
Your new email subject line had 45% open rate on 20 emails. The old one had 35% open rate. Better subject line?
Maybe. Or maybe just random variation. With 20 emails, the “true” open rate could easily be anywhere from 25% to 65%. You’ve learned almost nothing useful. I made this exact mistake early on, declaring a subject line the “winner” after testing it on 30 subscribers. The next send with the same line performed worse than the original. Lesson learned.
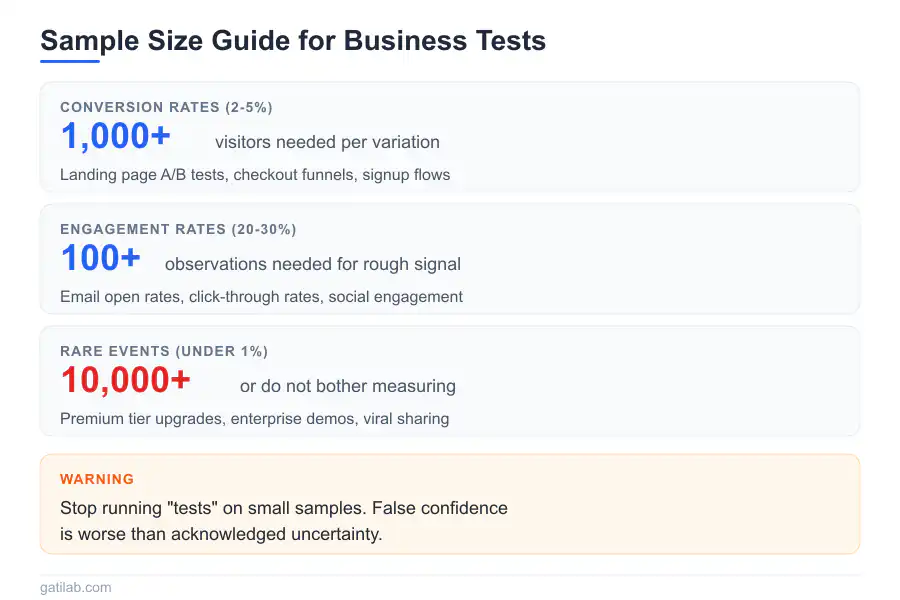
Rules of thumb for sample sizes: For conversion rates around 2-5%, you need 1,000+ visitors to detect moderate differences reliably. For rates around 20-30%, you need 100+ visitors for a rough signal. For rare events (under 1%), you need massive samples or don’t bother measuring with precision. The rarer the event, the more data you need.
The practical implication:
Stop running “tests” on small samples. Either wait for enough data or make decisions on other grounds entirely. Small sample tests give you false confidence, not real information. False confidence is worse than acknowledged uncertainty because it leads you to commit resources to conclusions that might be wrong.
Understanding Variance
Averages hide important information. Variance matters as much as central tendency, sometimes more.


Two freelancers both average $10,000/month income.
Freelancer A: Consistent $9,000-$11,000 every month. Predictable. Plannable.
Freelancer B: Wild swings from $2,000 to $25,000. Same average, completely different experience.
Same average. Completely different businesses. Freelancer B might have cash flow crises despite having the same average income as Freelancer A. I’ve been both of these freelancers at different stages of my career. The variance matters far more for daily life than the average.
Business applications:
Project duration: “Average 4 weeks” might mean “always 4 weeks” or “anywhere from 2 to 8 weeks.” Very different implications for scheduling and client expectations.
Revenue: “Average $50K/month” might mean stable or volatile. Different implications for when you can safely hire.
Customer lifetime: “Average 18 months” might mean most customers stay around 18 months, or half leave after 3 months while half stay for 33 months. Different implications for customer service investment.
Measuring variance:
Standard deviation quantifies spread formally. But even simpler: track the range. What’s the minimum and maximum you’ve seen?
“Revenue averages $50K with a range of $35K-$70K” tells you more than “revenue averages $50K.” I report ranges to myself, not just averages. The range is where the real information lives.
Regression to the Mean
Extreme results tend to be followed by less extreme results. This is math, not fate. And it trips up business owners constantly.
If this month was unusually good, next month will probably be more normal. Not because success causes failure. Because unusual performance is, by definition, unusual. It’s a statistical artifact, not a curse.
The mistake you’ve probably made:
You try a new marketing strategy. Have an amazing month. Credit the strategy. Next month is mediocre. Conclude the strategy stopped working.
But maybe the amazing month was random variation that would have happened anyway. The mediocre month was regression to the mean. The strategy might have done nothing either way. I’ve credited and blamed strategies for results they had nothing to do with. Multiple times.
The reverse mistake:
You try something new during a terrible month. Next month improves. You credit the change.
But regression to the mean means bad months are usually followed by better months regardless. The change might have been irrelevant.
Practical implications:
Don’t overreact to single data points, especially extreme ones. Wait for multiple observations before concluding anything. Look for patterns across months, not isolated events.
If performance is unusually good or bad, expect it to normalize. Budget accordingly. Understanding your financial KPIs helps you distinguish signal from noise in your numbers.
Selection Bias
The data you see might not represent reality. This one is subtle and everywhere.


You survey your existing customers about satisfaction. 90% are satisfied. Great news!
But you only surveyed people who stayed. The dissatisfied ones already left. You’re not measuring customer satisfaction. You’re measuring survivor satisfaction. Those are very different things.
In business:
Successful freelancers blog about how to freelance. Failing freelancers quit quietly and disappear. Survivor bias makes freelancing success look more common and easier than it actually is.
Companies share case studies of projects that went well. Nobody publishes their failures. Selection bias distorts the perceived success rate of everything from marketing tactics to business strategies.
Your most engaged customers give feedback. Silent customers have different experiences you never hear about. The feedback you collect is systematically biased toward people who care enough to respond.
Combating selection bias starts with one question: Who isn’t in this data? Actively seek data from people who didn’t respond, didn’t convert, and didn’t stay. Their absence is information. Sometimes it’s the most important information.
The Multiple Testing Problem
Run enough tests and something will appear significant by chance. This is pure mathematics, not pessimism.
You test 20 different marketing messages. One has significantly higher conversion. Victory!
But with 20 tests at a 5% significance level, you expect 1 false positive purely by random chance. Your “winner” might be noise that happened to cross your threshold.
Business version:
You analyze customer data looking for patterns. You test age, gender, location, device, time of day, referral source, and 15 other variables. You find that customers from one particular city convert 40% better.
Is this real? Or did you find one random correlation among the many you tested? If you test enough variables, you’ll always find something that looks significant. That doesn’t mean it is.
The solution:
Pre-register hypotheses. Decide what you’re testing before you look at data. If you’re exploring data for interesting patterns, treat findings as hypotheses to test later, not conclusions to act on now.
Adjust significance thresholds when running multiple tests. The more tests you run, the stricter your standard for believing any individual result should be.
Replicate before committing resources. If a pattern is real, it should show up again in new data. If it only appeared once, be skeptical.
Correlation vs. Causation
The most common statistical error in business, and the most expensive one.


Customers who use your premium features have higher retention. Conclusion: Push everyone to use premium features to improve retention.
But wait. Maybe customers who were already likely to stay chose to learn premium features because they were invested in the product. The correlation exists, but the causal direction is backwards. Pushing features on uncommitted customers won’t make them stay.
Common business confusions:
“Users who complete onboarding retain better.” (Maybe engaged users naturally do both, and onboarding completion is a symptom, not a cause.)
“Pages with more content rank higher.” (Maybe topics that require depth naturally need more words, and adding fluff to short pages won’t help.)
“Faster-responding salespeople close more deals.” (Maybe easier deals get answered faster because they’re simpler, and speed isn’t the variable that matters.)
Establishing causation:
Controlled experiments. Hold everything else constant, change one thing, measure the effect. This is the gold standard.
Time ordering. Cause must precede effect. If B happened before A, A didn’t cause B.
Mechanism. Can you explain why one thing would cause another? If the causal pathway makes no logical sense, be skeptical.
Rule out confounders. What else could explain the correlation?
Most business data is observational. Correlations are starting points for investigation, not conclusions to act on. This matters whether you’re building a SaaS business or running a consultancy.
Practical Statistical Thinking
You don’t need to run formal analyses. You need to think statistically about your data and your decisions.
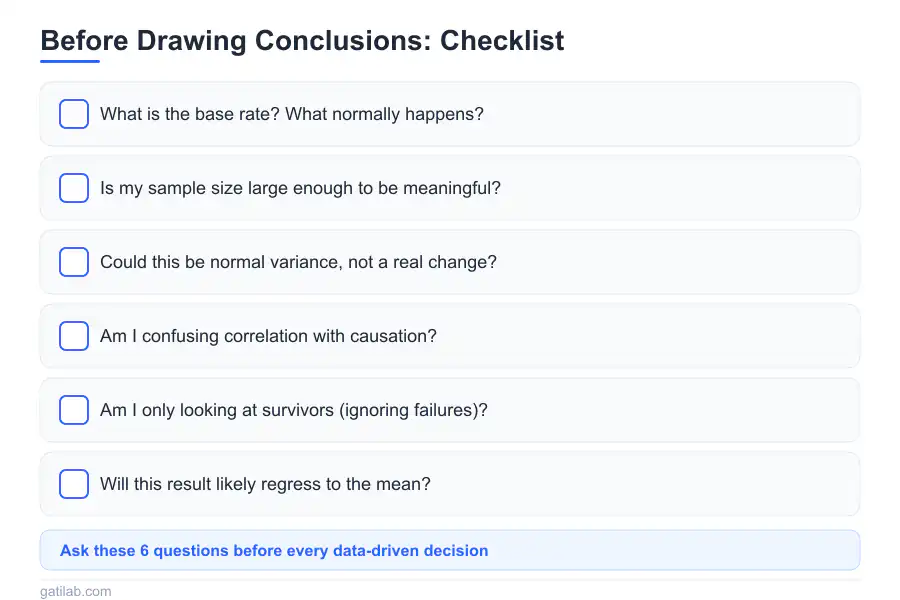
Before drawing conclusions, ask:
- Is the sample size large enough to trust?
- What’s the base rate I’m comparing against?
- Could this just be random variation?
- Who’s missing from this data?
- How many things did I test before finding this result?
- Is this correlation or causation?
When making decisions, ask:
- What’s my confidence level in this data?
- What would I do if this pattern disappeared next month?
- Am I overreacting to a single data point?
- Am I seeing what I want to see?
When evaluating claims from others, ask:
- What’s the sample size?
- What’s the comparison group?
- Could selection bias explain this?
- Is this an average or a guarantee?
I keep these questions printed next to my monitor. Not because I always remember to ask them, but because the times I forget are the times I make expensive mistakes.
Common Business Statistics Mistakes
Mistake 1: N=1 conclusions
“We tried that once and it didn’t work.”
One attempt proves nothing. Randomness affects single trials enormously. You need multiple attempts to draw meaningful conclusions. I’ve abandoned strategies after one failed attempt that probably would have worked if I’d given them three tries.
Mistake 2: Anchoring on round numbers
“We need at least 100 customers before this matters.”
Why 100? What’s magical about that number? Round number thresholds are arbitrary. Think about what sample size actually tells you statistically rather than picking a nice-looking number.
Mistake 3: Ignoring the null hypothesis
“The new approach had 8% conversion vs. 7% before. It’s working!”
The null hypothesis is that nothing changed. Can you actually reject that with your data? Or is 8% vs 7% within normal variation? With small traffic, a 1% difference often means nothing at all.
Mistake 4: Confirmation bias in data
“Let me check if this strategy is working.”
You’ll find evidence for whatever you’re looking for if you search selectively. Look for evidence against your hypothesis instead. If you can’t find disconfirming evidence even when looking for it, you might actually be onto something.
Mistake 5: Treating estimates as certainties
“This project will take 6 weeks.”
No, that’s an estimate. The project will take 4-8 weeks with 6 as the point estimate. Planning as if 6 weeks is certain guarantees disappointment when variance inevitably happens. I’ve learned to communicate ranges instead of single numbers to clients. It manages expectations more honestly.
Building Statistical Intuition
Statistical thinking is a habit you build, not a technique you apply occasionally.
Practice skepticism:
When someone claims impressive results, ask about sample size. When data shows exciting patterns, ask what’s not being shown. When successes are celebrated, ask about the failures that weren’t mentioned.
Embrace uncertainty:
Replace “will” with “probably.” Replace point estimates with ranges. Acknowledge what you don’t know alongside what you do know. Honest uncertainty is more useful than false precision.
Wait for data:
Don’t conclude from early results. Let experiments run to completion. Gather enough information before deciding. The cost of waiting a week for better data is almost always lower than the cost of acting on bad data.
Update beliefs:
When new data contradicts old beliefs, update your beliefs. Don’t dismiss data because it’s inconvenient. Don’t cling to initial interpretations because changing your mind feels uncomfortable.
Think in probabilities:
“This might work” is more honest than “This will work.” “There’s a 70% chance” is more useful than false certainty. I try to attach rough probability estimates to predictions. It forces me to acknowledge uncertainty rather than pretending it doesn’t exist.
Statistical thinking protects you from your own cognitive biases. It slows down decision-making just enough to make genuinely better decisions. The goal isn’t mathematical precision. It’s intellectual honesty about what you actually know versus what you’re assuming.
This thinking applies to every business decision, from pricing your services to evaluating marketing results to deciding which clients to pursue.
Data-Driven Decisions FAQ
Frequently Asked Questions
What is base rate blindness and why does it matter in business?
Base rate blindness means evaluating numbers without knowing what is normal. Your campaign generated 15 leads, but is that good? Without knowing you normally get 5 or 20 leads per week, the number is meaningless. Three complaints from 50 customers is alarming. Three from 5,000 is excellent. Track metrics over time to establish what normal looks like, including the range not just the average, so you can distinguish genuine changes from random variation.
How large should my sample size be for reliable business conclusions?
For conversion rates around 2-5%, you need 1,000 or more visitors to detect moderate differences reliably. For rates around 20-30%, you need 100 or more for a rough signal. For rare events under 1%, you need massive samples. A 45% open rate on 20 emails means almost nothing because the true rate could be anywhere from 25% to 65%. Small sample tests give false confidence, not real information, which is worse than acknowledged uncertainty.
What is regression to the mean and how does it trick business owners?
Extreme results tend to be followed by less extreme results. This is math, not fate. If this month was unusually good, next month will probably be more normal. Business owners commonly try a new strategy during a great month, credit it for the results, then see a mediocre next month and blame the strategy. But the great month may have been random and the mediocre month was regression to the mean. Wait for multiple observations before concluding anything.
How do I avoid selection bias in my business data?
Always ask: who is not in this data? Customer satisfaction surveys only reach people who stayed, so dissatisfied customers who left are invisible. Success stories only include winners because failures quit quietly. Your most engaged customers give feedback while silent customers have different experiences. Actively seek data from non-respondents, non-converters, and churned customers. Their absence is information, sometimes the most important information you could have.
What is the multiple testing problem and how do I avoid it?
Run enough tests and something will appear significant by chance. Testing 20 marketing messages at 5% significance means expecting 1 false positive randomly. Solutions: pre-register hypotheses before looking at data, adjust significance thresholds when running multiple tests, treat exploration findings as hypotheses to test rather than conclusions to act on, and replicate before committing resources. If a pattern is real, it should show up again in new data.
How do I distinguish correlation from causation in business data?
Ask four questions: Can you run a controlled experiment? Does the cause precede the effect in time? Can you explain why one thing would cause another? Have you ruled out confounding variables? Customers who use premium features may retain better not because features cause retention, but because already-committed customers choose to learn features. Most business data is observational, so correlations are starting points for investigation, not conclusions to act on.
Why is understanding variance important beyond just averages?
Two freelancers both averaging $10,000 per month live completely different lives if one ranges from $9,000-11,000 and another from $2,000-25,000. Same average, completely different experiences. Project duration averaging 4 weeks might mean always 4 weeks or anywhere from 2 to 8 weeks, with very different implications for scheduling. Track the range alongside the average. Revenue averages $50K with a range of $35K-70K tells you more than just the average alone.
What questions should I ask before making data-driven decisions?
Before drawing conclusions: Is the sample size large enough? What is the base rate for comparison? Could this be random variation? Who is missing from this data? How many things did I test before finding this result? Is this correlation or causation? When making decisions: What is my confidence level? What would I do if this pattern disappeared next month? Am I overreacting to a single data point? Am I seeing what I want to see?